
- ◇ アノキミモノガタリその伍・∞
- はじめに
- 最適な自己流のID設計
- 需要に応じて最適なパーツを組み合わせる
- Ulid-Flake:64-bitのBitInt型のULID設計
- Ulid-Flakeの実装イメージ
- Ulid-Flake のimplementationについて
- 感想
- 最後に
- IDシリーズ記事の一覧
◇ アノキミモノガタリその伍・∞
アノ日のULID、キミとまた出会えるまで十億億回の輪廻のタイムスリップ、A.D.10889年まで。

キミに、A.D.10889年の8月2日、UTC黎明5時31分50秒、655ミリ秒、
やっと、ULID宇宙の最後の1ミリ秒で、キミと再会できた。
7ZZZZZZZZZK4SANAG1ZM5T2K9Zよ、キミ。
忘れられない、なんと可愛らしく、愛しいその目。
たとえ、八千八百年、一万年、一千万年、を経っても、
たとえ、十億回、十兆回、十京回、輪廻しても、
アップロードされても、ダウンロードされても、コピーされても、
キミはキミで、何も変わっていないようにしか見えないだろう。
ずっと過去のその瞬間に執拗に拘ったぼくが愚かだった。
現在の僕はようやく悟った。
+1ミリ秒で、宇宙、崩壊、システムクラッシュ、
そして、涅槃、再生へ、もう1回の輪廻。
我々は、きっと、広大なネット上で、
どっかで、また再会できるだろう。
わが征くは星の大海。
はじめに
こんにちは、転生したら相変わらずエンジニアだった OLTA(オルタ)プロダクトグループ研究開発チームのタイトルの前置きがとにかく長い B.です。
INVOYカードの開発を担当しています。
今回、UUID*1のRFCがRFC4122からRFC9562に刷新されたことをきっかけに、約2年間眠っていたテックブログの記事を加筆して発表しようと思います。
工程編ではPythonにおいてULIDの実応用とか、実際のDjango/DRF工程において起こった様々な問題について話しました。最後のの実戦編ではどのようにニーズに応じて最適な自己流IDを設計するかについて詳しく述べます。
最適な自己流のID設計
もし特別な需要がなければ、基本的に上記に紹介したUUID v4、UUID v7またULIDの利用を推奨しています。一方、もっと小さいなサイズで利用したいやDecimal方式で表現したい、分散システムでも単調増加確保できるメカニズムが欲しいなどのようなカスタマイズしたい部分があれば、Snowflakeのように自己流のIDを設計するしかありません。
需要に応じて最適なパーツを組み合わせる
前文で紹介した主流のID仕様を見れば分かるかもしれませんが、大抵のパータンは幾つかの分けて似てきています。そこで、欲しい機能の要素を拾って組み合わせば、簡単に自己流のIDが設計できます。
-
適切なサイズを設計します。
-
16-bit、32-bit、64-bit、128-bitなど、基本的にきっちり1-byteで割れるサイズが推奨です。
-
-
十分に分散的な分布になる、セキュリティ的な、推測しにくいIDが欲しい場合:「乱数パーツ」
-
システムや事業の規模を想定して、適宜数ビットのランダム値を採用します。
-
乱数発生器を暗号学的に安全な乱数生成メカニズムにします。
-
利用するビット数が増えれば増えるほど、衝突耐性があがります。一方で、サイズが増えることで、IDを保存するために必要なストレージ容量も増えるので、パフォーマンスに影響が出ます。なぜなら、IDのサイズが大きくなると、データベースのインデックスサイズも大きくなり、クエリのパフォーマンスに影響を与える可能性があります。
-
-
単調増加(Monotonicity)の特性が欲しい場合:「タイムスタンプパーツ」
-
先頭に数十ビットにUNIXタイムスタンプを採用します。
-
需要に応じて、時間の精度の単位をミリ秒にしたり、マイクロ秒にしたりして調整します。
-
UNIXタイムスタンプは協定世界時 (UTC) 1970年1月1日0時0分0秒から始まるために、何年までこのシステム働かせる必要があるのかを見極めて適宜ビット数を設計します。
-
基本的に1970年から始まるUNIX Epochを開始値とするのが推奨ですが、場合によって、短いタイムスタンプビット数で、最大限にタイムスタンプのビットを利用したい場合、別の開始値を設定するのもありです。例えば、Snowflakeでは独特のエポックの協定世界時(UTC)2010年11月04日1時42分0秒を採用しました。同じくSnowflake式IDを採用したDiscordでは協定世界時(UTC)2015年1月1日0時0分0秒を開始値としました。
-
-
最小の時間単位精度内で、ランダムの部分の単調増加性を確保したい場合:「自動+1ビットの乱数パーツ」
-
分散システムでも衝突しない完全な一意性を確保したい場合:「ノードパーツ」
-
事業やシステムの需要に応じて、SnowflakeのようにWorkerID (DataCenterID + MachineID)を設けるのも良いし、MongoDBのObjectIDのようにMachineIDやProcessID利用して何かのランダム値を生成するのも良いです。
-
ただし、Snowflakeのように、完全な時刻の協調と衝突回避するための待機仕組みを持たせるには、インフラの面の設計や設定コストも存在するために要注意です。
-
また、分散システムにおいて、一意のWorkerID やMachineIDを取得するには、Apache ZooKeeperのような設定情報の集中管理や名前付けなどができるサービスが必要かもしれません。
-
Ulid-Flake:64-bitのBitInt型のULID設計

例えば、このようなビジネスを想像してみましょう。業務として大抵秒間1個くらいのIDが作成されるのが平均値です。一方、繁忙期に稀に同じミリ秒内でも1個以上のIDが作成される可能性があります。また、スモールビジネスなので、小規模のマルチPodを利用したり、分散システムは利用せずシングルDBを利用してたりします。ユーザーには問い合わせする時にできるだけコンパクトで短くて視認性が良い文字列が良いです。絶対的な単調性よりは、ある程度の単調性を保証する上で、推測の困難性を重視します。一方、推測しやすさはセキュリティには特に影響が出るほどではなく、あくまでも、生成されたIDの序列からは事業の規模や変化率を推測不能にしたり、また、とあるユーザーのアカウントで生成されたIDを利用して+1でそのままほかのユーザーのIDを当ててしまったりして、サーポートや問い合わせなどの時に紛らわしいことなどを下げたいくらいです。また、100年以内で利用できれば問題ありません。自分はこのようなビジネスをslow-small-season-bussinessを呼んでいます。
この場合、ULIDは素晴らしいですが、128-bitはやっぱり長すぎて半分の64-bitにしたいです。また、ULIDはAD10889年まで利用できますが、これから数百年内で利用できるシステムであれば問題がないので、タイムスタンプは42 ~ 48 bitくらいにしたい。Base32のエンコード方式も維持したいので、5bits/charsの情報量にて20-bitは4桁でちょうどきっちりなので、ランダムの部分は20-bitにします。20-bitはULIDの80-bitと比べて、確かに約10億(2^30)倍で衝突耐性は低下しますが、ただの1,024回の試行回数で衝突になります。一方、分散システムを利用しない限り、またシングルDBの場合、自動インクリメントのメカニズムさえ設ければ、特に問題ではありません。
こうなると、タイムスタンプの部分は44-bit利用できます。44-bitの場合、少なくともBase32文字列で9桁が必要です。9桁のBase32文字列は45-bitの情報量を持ちますので1-bitは捨てます。さらに、ちょうど同じく64-bitのBitIntとの互換性も欲しいために、44-bitのタイムスタンプは1-bitの符号ビットを除いて43-bitになります。また、実質64-bitのBitIntとして、Django Modelにおく場合、特別のUUID fieldやULID fieldを利用せずに、BitInt fieldとしてもシンプルに利用できます。
そのほか、分散システムはあまり考慮せず、workerの部分は設けないが、20-bitのランダム値は、p=0.5時に、2^(20/2)=1,024の試行回数の期待値を有します。一方、もし、違うPodでの分散システムで利用したい場合、さすがに1,024の試行回数では衝突耐性が低いです。同じミリ秒内で1個以上のIDが生成される可能性が低いシステムのいて、もう十分に考えられます。しかし、分散システムにおいて、ほぼ確実に衝突します。つまり、同じPodの場合、自動インクリメントのメカニズムがあるので、衝突しないことが保証されています。ちがうPodの場合、またID発行・協調サーバーを置かない限り、衝突しないことが保証されません。そこで、分散システムにおいて、何かの拡張性用のScalabilityIDのようなパーツが望ましいです。ここでは、Scalabilityに1桁(5-bit)を設ける予定です。残りの15-bitはランダム値になります。
したがって、以上のニーズを考慮し、以下のように自己流のIDを設計しました。
-
適切なサイズを設計します。
-
サイズ的にちょうど良い整数型BitIntとの互換性が欲しいので64-bitにします。
-
-
単調増加(Monotonicity)の特性が欲しい場合:「タイムスタンプパーツ」
-
最小の時間単位精度内で、ランダムの部分の単調増加性を確保したい場合:「自動+nビットの乱数パーツ」
-
残りの20-bitはすべてランダム値にします。衝突耐性において、p=0.5時に2^(20/2)=1,024の試行回数の期待値を有します。
-
各時間の単位精度内で、初期値をランダム値にします。
-
継続的にIDを生成する場合は、+nビットランダム値のメカニズムを作ります。これでランダム値の部分も単調性を保ち上で、+1ビットの連番ではないため、推測しにくくなります。
-
Base32において、4桁で最大値はZZZZになります。
-
-
分散システムでも衝突しない完全な一意性を確保したい場合:「ノードパーツ」
-
分散システムを利用する場合、前述の乱数パーツを20-bitから15-bitに短縮します。
-
最後の5-bitをScalabilityIDとして設けまさす。
-
32通りの組み合わせの配置できます。中小規模の分散システムには十分です。
-
-
-
デフォルトの文字の序列化方式は、同じサイズが64-bitの整数型BitIntとの互換性が欲しいのでDecimalはにします。
-
一方、Base32は1桁の文字でDecimalやHexより多くの情報量が持つために、視認性も良くてシンプルで短いので、Base32方式も選択できるようにします。
-
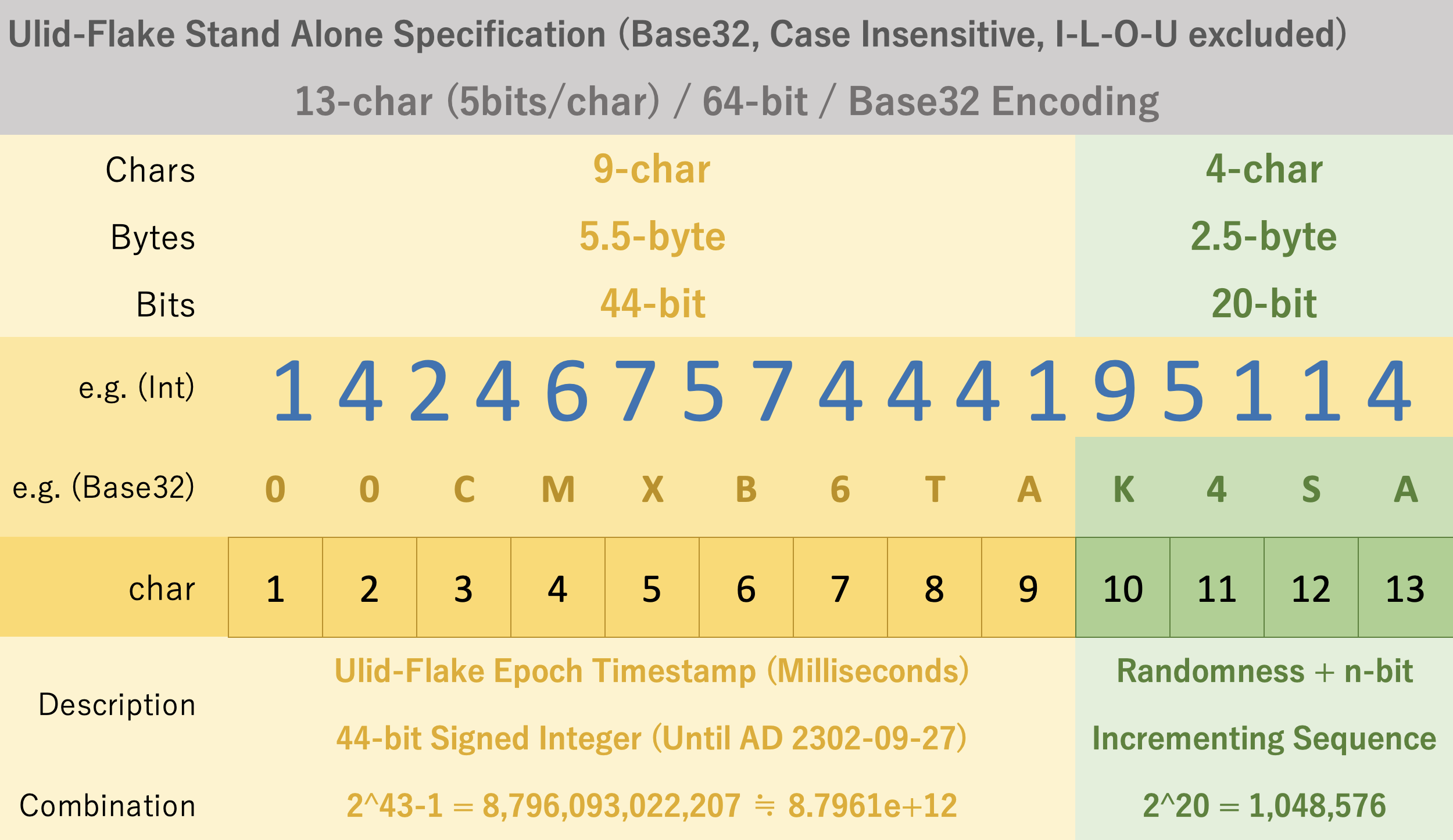
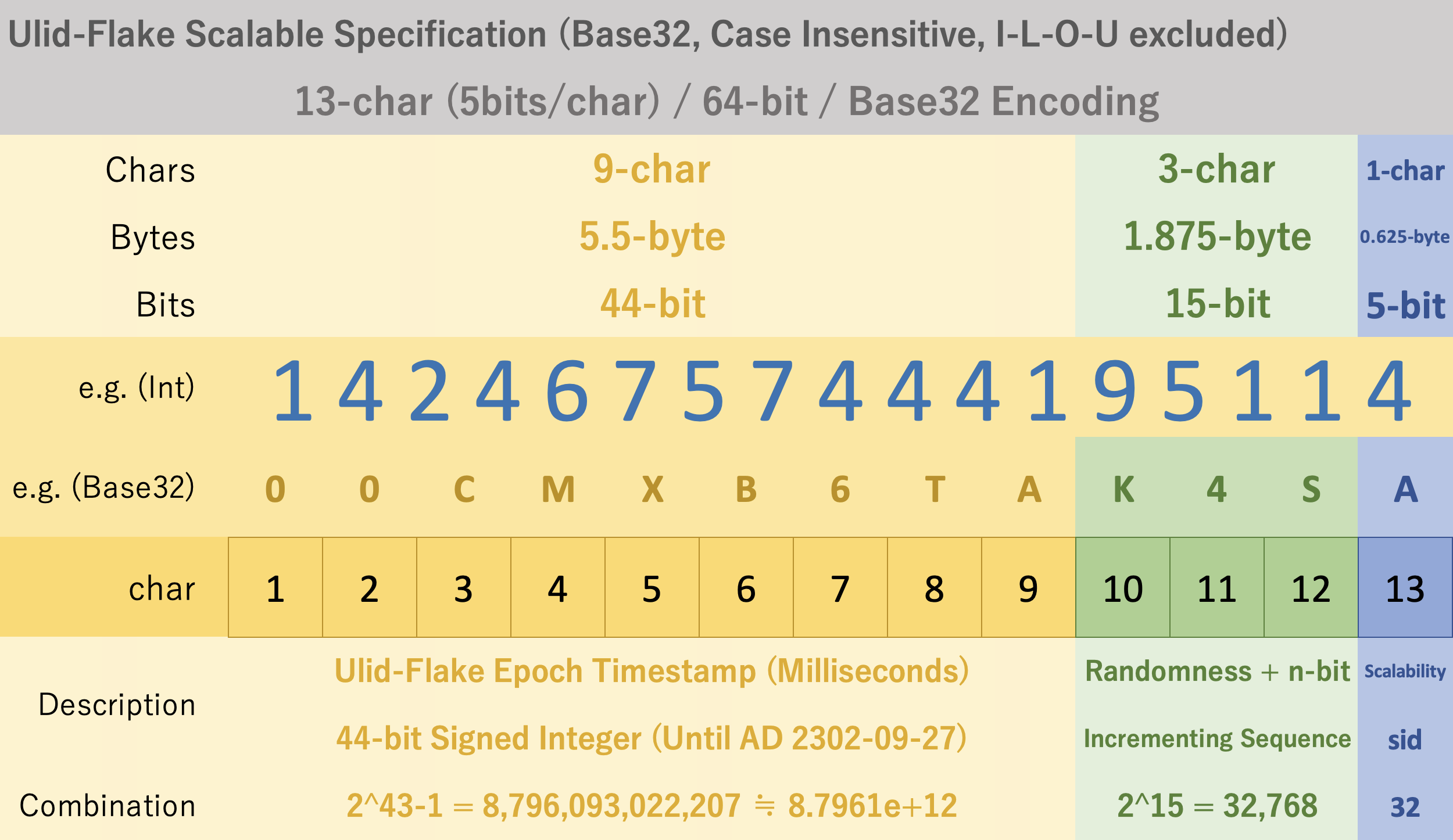
Ulid-Flakeの実装イメージ
ここではイメージとして、上記で設計したUlid-Flakeをpythonで実現してみます。
pythonのthreading.Lock()を利用して、同じミリ秒内で生成されたIDの自動インクリメントや衝突回避を確保しています。この実装では、auto_incrementの部分のイメージをわかりやすく説明するために、+nビットでなく、+1ビットで実装しました。実際には+entropyの感じで実装しましたので、詳細はこちらのGithubのrepositoryまで足を運んでいただればと思います。
実装したUlid-Flakeを使って見ましょう!
Ulid-Flake のimplementationについて
自分がslow-small-season-bussinessと称する中小企業向けのID生成案のUlid-Flakeの仕様に関する詳細はこちらをご覧ください。
https://github.com/ulid-flake/spec
また、以上のPythonの実現に関するもっと詳しい情報はこちらのGithubのrepositoryを参考になればと思います。
https://github.com/ulid-flake/python
現時点、Python、Go、Elixirの3つの言語のimplementationを実装しました。もし興味がある方は是非ほかの言語や、また既にあるPython/Go/Elixir版にもっと良い実現方法があると思う方など、是非積極的プルリクエストや、新しいRepositoryを作成して投稿してください!
既存のUlid-Flakeの仕様について、もし疑問点やご意見があれば、ぜひ積極的githubのspec repositoryで、proposalなどをご指摘ご提案ください!
感想
今回の熱熱ある技術負債の解消対応は、2022年6月17日にチケットを立てて、6月20日から正式的に着手して、正式的に完了したら、ふと振り返て見ると、すでに6月30日の夕方頃の月末でした。ほかのチケットを兼ねながらトータル11日も消費してしまいました。正直、最初は「IDの型を変えるくらいで、せいぜい3、4日、共存させたい場合、多くても5、6日かな」と思ってましたが、予想以外の問題が止まらないくらい次から次にちょこちょこ出ていました。また、2年後の現在、振り返って見ると学びも多く、そこから自分が学んだ知見を上記のTechBlogの文章に注力し、やっと記事としてまとめることができました。
エンジニアの道はやはり、どのくらい長くの経験を持っていても、どのくらいに自分がたくさんの知識を持っていると勝手に思っても、前方に未知の挑戦は必ず何度も何度でも、良い意味で君の自信を毎回毎回砕いて行く、砕いてやってくるので、そして毎回毎回それを乗り越えたら、逆に変に前より自信が上がって行き、強くになったと錯覚してしまい、そして、また次に向かて、砕いて砕いて、自分がやはり愚か者だなと自覚されるまでに、どんどん前進します。
みなさんに贈りたい言葉はただひとつだけです。これは実は名作アニメ『天元突破グレンラガン』のカミナ兄貴から主人公のシモンに贈った言葉でもあります。
お前を信じろ。俺が信じるお前でもない、お前が信じる俺でもない、お前が信じるお前を信じろ。
我が征くは星の大海。
最後に
今回、システムの記録番号を整数型自動採番から辞書式順序でソートできるULIDへの変更を行った事例、また事業のニーズに合うID案は既存のIDシステム中には存在しない場合、どのように最適な自己流のIDを設計するかについてを紹介しました。もしご参考になればとてもうれしいです。
OLTAでは Tech Vision の元、一緒にユーザーに価値を提供し、その結果事業を成長させるサービス作り続けるための仲間を募集しています。 もし、この投稿にご興味を持っていただいたら、是非カジュアルにお話しさせてください。
IDシリーズ記事の一覧